Dealing duplicate values in Python
- Ekta Aggarwal

- Jan 28, 2021
- 2 min read
Updated: Jan 29, 2021
In this article we will learn about how to find duplicates and drop then using pandas
Let us firstly import our library pandas as pd
import pandas as pdDataset:
Let us create a dataset which we will use for this tutorial
data = pd.DataFrame({
"Product_Category" : ["Makeup","Makeup","Makeup","Cold_drinks","Sauces","Sauces"],
"Sales" : [15000,15000,10000,23454,7800,9000]})
data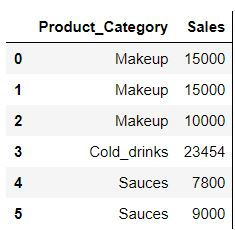
duplicated( ) function
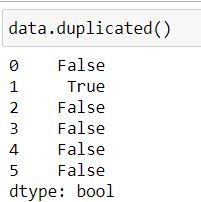
Pandas' duplicated( ) function when used with a dataframe returns a boolean series where True indicates that entire row has been duplicated.
data.duplicated()In the above dataset our row at index 1 (second row) is a duplicate thus duplicated( ) has returned a series where second element is True and rest are False (False denotes that the value is a unique value)
We can use the above boolean series to filter our dataset: To get a dataset with only duplicates :
data.loc[data.duplicated(),:]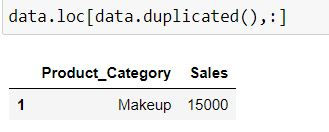
By default Python considers first occurence as unique occurence (ie. row with index 0) and all other repetitions as duplicates (row with index 1). This is because by default keep = "first" in duplicated( ) function.
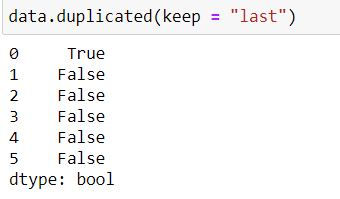
To keep the last occurrence as unique and all others as duplicate we set keep = "last"
data.duplicated(keep = "last")Note that now row with index 0 has True (i.e. it is a duplicate) while row with index 1 is False (it is being considered as unique)
data.loc[data.duplicated(keep = "last"),:]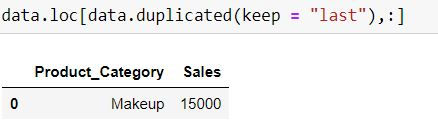
When keep = False then Python treat all of the repetitions (including first and last occurrence as duplicates)
data.duplicated(keep = False)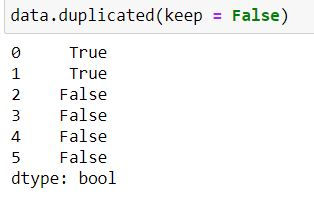
Dropping duplicate values
Using pandas' drop_duplicates( ) we can drop the duplicate values.
In the following code keep = "first" means first occurrence (at index 0 ) would be a unique value and hence would not be dropped.
data.drop_duplicates(keep = "first")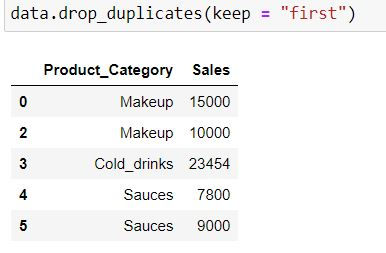
keep = "last" means last occurrence (at index 1) would be a unique value and would not be dropped.
data.drop_duplicates(keep = "last")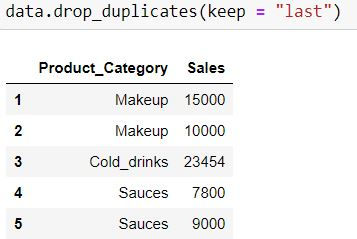
keep = False means all occurrence (at index 0 and 1) would be a treated as duplicates and hence would be dropped.
data.drop_duplicates(keep = False)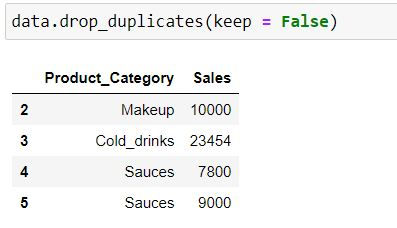
Finding duplicates on the basis of some columns:
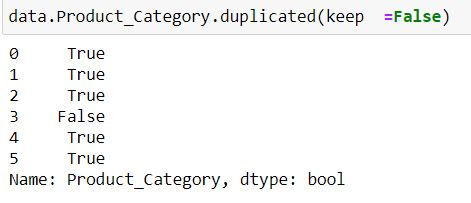
To find duplicated on the basis of Product_Category column we apply duplicated function to the single column and not on entire data:
data.Product_Category.duplicated(keep =False)Note: We have defined keep = False. Since Makeup and Sauces are repeated thus we have a True corresponding to their indices.
Task: Filter for those product categories which are unique.
In the code below we are filtering for duplicate product categories using duplicated( ) function and have then provided a negation using ' ~ ' symbol.
data.loc[~data.Product_Category.duplicated(keep =False),:]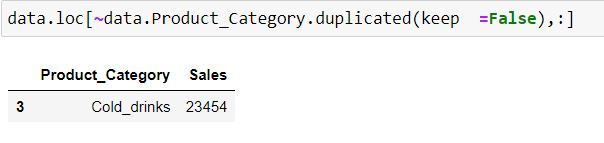



Comments